NVIDIA выпустила Nemotron 3 Nano Omni — мультимодальную модель, которая обрабатывает экраны, документы, аудио, видео и текст в одной перцептивной петле. Модель появилась с дня релиза на Hugging Face и в каталоге AWS SageMaker JumpStart. NVIDIA позиционирует её как «один эффективный открытый вес для агентного рассуждения», не как ещё одну добавку к существующему стеку.
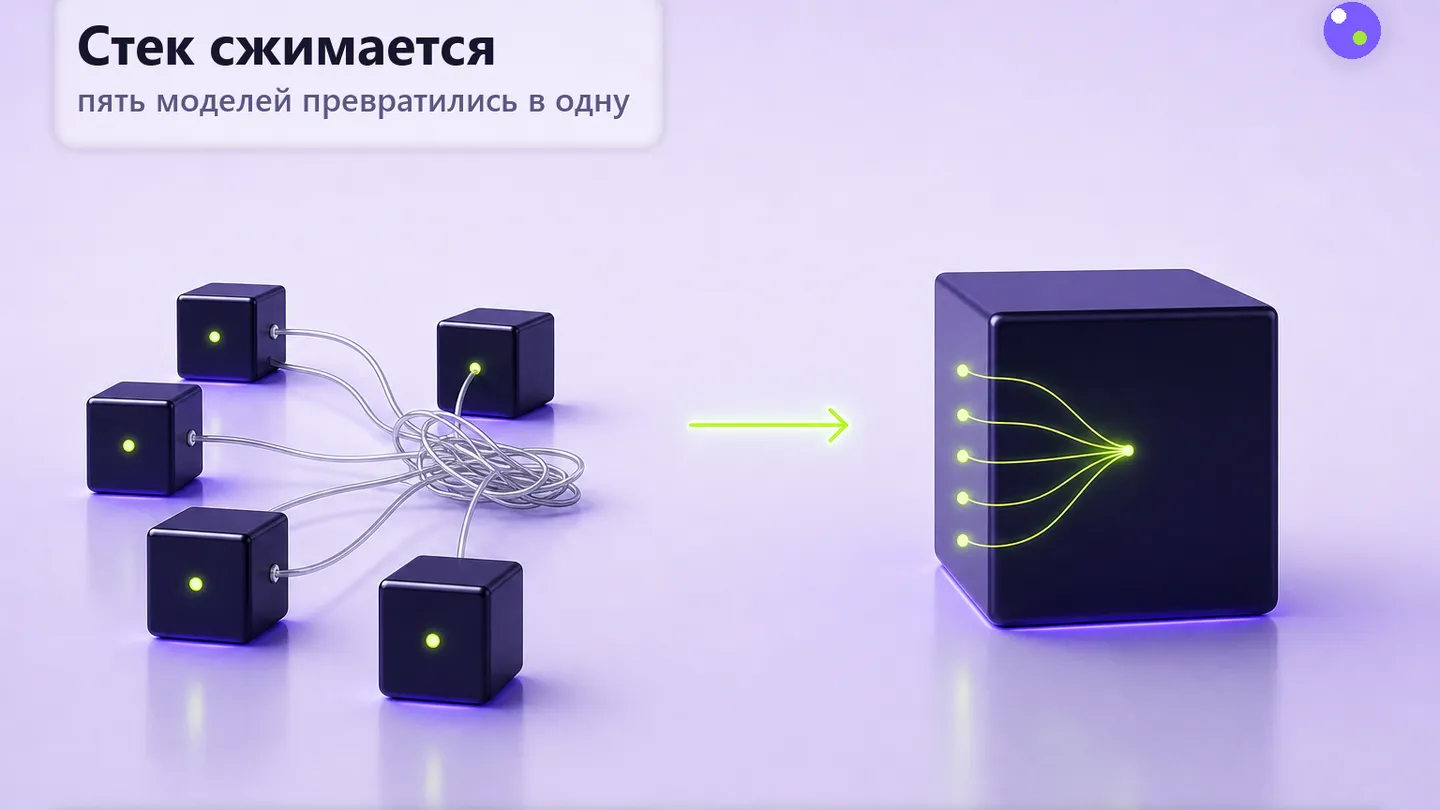
Главный посыл — техническая структура. Раньше агент собирался из цепочки: одна модель распознавала экран, вторая читала документ, третья обрабатывала голос, четвёртая писала текст, и поверх этого работал оркестратор-роутер с маршалингом контекста между ними. У этой схемы было три проблемы: задержка (каждый переход — отдельный inference), стоимость (за каждый узел платится отдельно), и сложность governance (каждую модель нужно отдельно сертифицировать, отдельно обновлять, отдельно мониторить). Nemotron 3 Nano Omni убирает все три за счёт того, что одна архитектура держит все модальности в одном prefill’е.
Это уже видели в других слоях стека. x86 в 1980-х поглотил математические сопроцессоры (Intel 8087, 80287, 80387), которые до этого были отдельными чипами для floating-point. Сначала сопроцессоры были быстрее и точнее, потом x87 встроили в основное ядро (486DX) — и отдельный сопроцессор перестал иметь смысл. GPU в 2010-х поглотила специализированные DSP-чипы для обработки сигналов и звука: одно вычислительное ядро оказалось эффективнее, чем набор узкоспециализированных. Сейчас тот же сюжет идёт в моделях. Дробный стек был оправдан, пока в каждой модальности нужна была отдельная архитектура — теперь это не так, и одна модель ловит все потоки.
Что это значит для корпоративного покупателя. До этого релиза типовой корпоративный агент стоил столько, сколько стоит сборка из 3–5 моделей плюс оркестратор. Из этих моделей одна-две — фронтирные (дорогие), остальные — специализированные (дешёвые, но требуют интеграционной работы). У объединённой модели цена сборки падает не за счёт скидки на единицу, а за счёт того, что нужно меньше единиц. Также падает governance-нагрузка: одна model card вместо пяти, один мониторинг вместо пяти. Это не сэкономит 80% бюджета корпоративного агента, но 30–40% — реалистично, и это уже значимо для CFO, который раньше отказывался подписывать пилот.
Российский корпоративный сегмент это уже коснётся через 6–9 месяцев. SageMaker JumpStart напрямую недоступен для российских юрлиц с 2022 года, Hugging Face — частично. Но Nemotron — это открытые веса, и они довольно быстро появляются в российских корпоративных каталогах через Сбер, MTS AI и подобных интеграторов. Внутри российского контура унификация стека будет идти примерно с тем же лагом, что обычно — около полугода после открытого релиза.
P.S. Стоит держать в уме, что унификация не отменяет специализированные модели сразу. x87 формально жил рядом с 486DX ещё лет десять — для серверных нагрузок, для embedded, для конкретных задач, где специализированный чип всё ещё был быстрее. Vision-only и speech-only модели тоже не исчезнут с этого релиза: они останутся в нагрузках, где требуется максимальная точность одной модальности или жёсткие ограничения по latency. Но дефолт корпоративного агента перестаёт быть дробным. Это и есть точка сдвига.